
近期,NovelAI 模型及源码的大规模泄露引起了大规模的讨论,与其相关的各种 colab 或者本地部署方法也在广泛传播。于此同时,腾讯(我没收钱)等云服务厂商也在大规模促销 GPU 型服务器实例。
有人就在询问了:如果有一台 Linux GPU 服务器,如何将 Stable Diffusion webui 及NovelAI 部署使用?
本文即是系统性的介绍其部署教程。
前期准备
在开始部署之前,你需要准备的:
- 一台带有 GPU 的 Linux 云服务器
(显存 > 8GB,但是这类服务器的专业卡应该没有弱的吧) - 已经安装了 Python,版本 > 3.10
(什么?不会安装?左转百度 Python 教程非常多)
在进行教程时,本人使用的云服务器:
- 8 核心 32 GB 内存,使用 NVIDIA Tesla T4 显卡(16 GB)
- Debian 9 操作系统(建议使用 Debian 或 Ubuntu,apt 部署不香嘛)
实测在 28 steps,采用 Euler a 采样,输出分辨率 384x640 时,能做到 5s 生成一张图片。
环境部署
[admonition title="权限警告" color="red"]不要用root用户执行安装脚本![/admonition]
安装依赖
Debian 系(包括但不限于 Debian,Ubuntu):
sudo apt install wget git python3 python3-venvRedHat 系(包括但不限于 RedHat,CentOS)
sudo yum install wget git python3一键安装
官方 repo 提供的一键脚本:
bash <(wget -qO- https://raw.githubusercontent.com/AUTOMATIC1111/stable-diffusion-webui/master/webui.sh)运行脚本会从仓库 git pull 最新版本,并安装 Pytorch,GFPGAN,CLIP 等依赖。
所需时间较长,请耐心等待。
如果一切成功,启动脚本会在安装完所有依赖后,提示如下内容:
Can't run without a checkpoint. Find and place a .ckpt file into any of those locations. The program will exit.这是提示用户没有正确放置所需模型,并自动退出程序。至此可以进行下一步。
加载模型
推荐使用 4GB 大小的 animefull-final-pruned 模型。(NovelAI 泄露模型地址)
模型泄露地址:
magnet:?xt=urn:btih:5bde442da86265b670a3e5ea3163afad2c6f8ecc&dn=novelaileak&tr=udp%3A%2F%2Ftracker.opentrackr.org%3A1337%2Fannounce&tr=udp%3A%2F%2F9.rarbg.com%3A2810%2Fannounce&tr=udp%3A%2F%2Ftracker.openbittorrent.com%3A6969%2Fannounce&tr=http%3A%2F%2Ftracker.openbittorrent.com%3A80%2Fannounce&tr=udp%3A%2F%2Fopentracker.i2p.rocks%3A6969%2Fannounce请注意,本次泄露的 50GB 文件,其中大部分无需下载使用。
我们需要下载到服务器的内容有:
- stableckpt/animefull-final-pruned/model.ckpt (文件)
对应放置到 webui 的 models/Stable-diffusion/final-pruned.ckpt - stableckpt/animefull-final-pruned/config.yaml (文件)
对应放置到 webui 的 models/Stable-diffusion/final-pruned.ckpt - stableckpt/animevae.pt (文件)
对应放置到 webui 的 models/Stable-diffusion/final-pruned.vae.pt - stableckpt/modules/modules/ (目录及文件)
对应放置到 webui 的 models/hypernetworks/
下载并放置模型文件后,webui 的 models 文件夹应至少包含如下内容:
├─Codeformer
├─deepbooru
├─ESRGAN
├─GFPGAN
├─hypernetworks
│ aini.pt
│ anime.pt
│ anime_2.pt
│ anime_3.pt
│ furry.pt
│ furry_2.pt
│ furry_3.pt
│ furry_kemono.pt
│ furry_protogen.pt
│ furry_scalie.pt
│ furry_transformation.pt
│ pony.pt
├─LDSR
├─Stable-diffusion
│ final-pruned.ckpt
│ final-pruned.vae.pt
│ final-pruned.yaml
└─SwinIR确认无误后,可以返回 webui。
启动参数
编辑 webui 根目录下的 webui-user.sh,找到如下位置:
# Commandline arguments for webui.py, for example: export COMMANDLINE_ARGS="--medvram --opt-split-attention"
export COMMANDLINE_ARGS=""在这里可以自定义 webui 启动时的参数。要使服务器对远程开放,我们需要 --listen 参数
将上面的参数修改为:
# Commandline arguments for webui.py, for example: export COMMANDLINE_ARGS="--medvram --opt-split-attention"
export COMMANDLINE_ARGS="--listen --port <你想使用的端口> --no-half-vae "通过如此设置,我们可以在特定的端口监听流量,开放 webui 的远程访问。(未定义 --port 时默认为 6969),且 --no-half-vae 能解决高分辨率下黑屏问题。
此时在浏览器访问 http://<服务器的IP>:<使用的端口>/ ,应该能够正常进入 webui 并产生图片了:
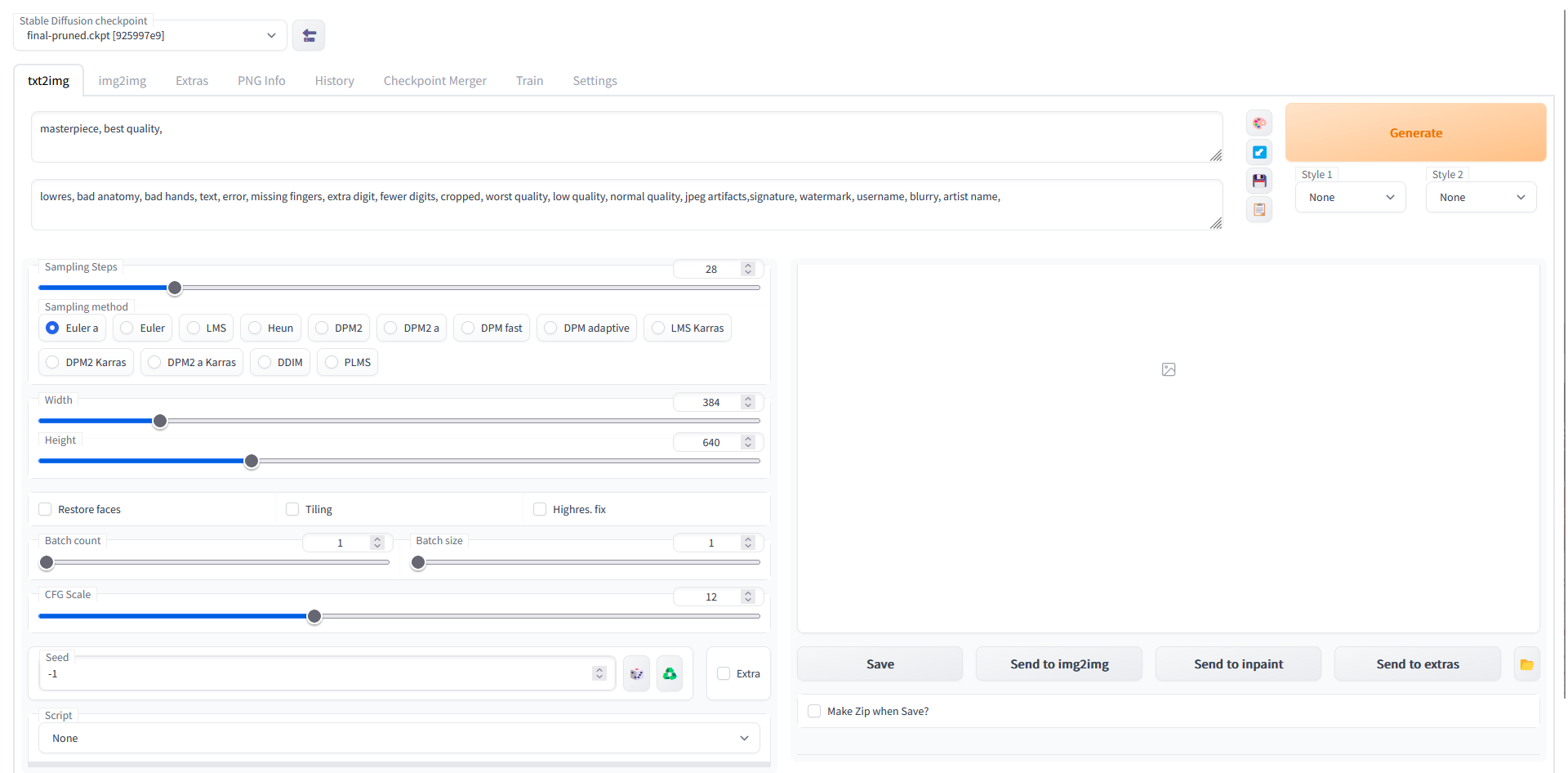
常见问题解答
Webui 的各项参数和 NovelAI 的有差别,但我又不想每次打开都要调整,应该怎么做?
- 请参考我的另外一篇文章:Stable Diffusion 默认采用 NovelAI 生成参数的修改办法
我就是不想用 ip:端口 的方式访问 Webui,应该怎么做?
- 在 webui-user.sh 添加启动参数,加入“--share”即可通过 gradio 生成有效期三天的分享链接。
分享/暴露到外网,前端容易被爬到然后滥用,应该怎么做?
- 在 webui-user.sh 添加启动参数,加入“--gradio-auth 用户名:密码”即可。
这样会在访问 WebUI 时要求访客提供对应的用户名和密码。
(直接访问端口和分享链接均有效) - 实际上被滥用还是次要威胁,你最需要担心的是远程代码执行漏洞。
Comments NOTHING